VISUALIZATION OF LARGE SAMPLES OF UNSTRUCTURED INFORMATION ON THE BASIS OF SPECIALIZED THESAURUSES
B.N. Onykiy, A.A. Artamonov, E.S. Tretyakov, K.V. Ionkina
National Research Nuclear University MEPhI (Moscow Engineering Physics Institute), Moscow, Russian Federation
Contents
2.1. Development of a thesaurus on monitoring objects
2.2. Information sources identification
Abstract
The database on “Nuclear materials and Advanced nuclear reactors” development stages are described in this paper. The database comprises items from various information sources of structured and unstructured types. The approach of received data visualization development as an unoriented graph was conducted in order to analyze the volume, structure, and particular cases of the data obtained. This method enables user to navigate between graph’s nodes through its edges in order to reveal hidden relations between database items.
Keywords: Graph, thesaurus, nuclear reactor, information retrieval, agents, data mining
1. Introduction
Information, as always and especially nowadays, is a strategic resource for decision-makers on key issues in the process of a particular technology or research development. Many research institutes, laboratories, commercial organizations and individual scientific and engineering groups all over the world are eager to receive relevant information about development of their scientific and technical field[1].
Information of this kind is published in a large number of international journals as scientific publications, on the websites of news agencies and sites of field-oriented companies and organisations as news reports.
Access to the mentioned information is carried out through the Internet. In the Internet information can be published in various forms. The amount of information, including non-core information for scientific organizations and research groups, is growing rapidly. This way, search for relevant information in the Internet without special tools, i.e. in the interactive mode, becomes hardly possible.
To date, there are many information retrieval systems (IRS), such as Google, Yandex, Baidu, which index information on the Internet round-the-clock and provide their results to its users[2]. Such IRS are aimed at a large sector of Internet users, i.e. the common user who most often forms his requests to find information about goods and services of their general purposes.
Thus, reference and full-text databases, that comprise publications from various scientific journals, are developed and introduced in order to navigate through the information in the specific field of science. The reference database "Web of Science" (Web of Knowledge) and a full-text database - "ScienceDirect" can be a good example of such databases[3],[4].
Such databases are effective tool for finding scientific publications of a certain author, however, if you need to find a cluster of information in a specific field, you have to use advanced queries and resort to a special syntax of the search tool, which does not guarantee the obtention of the pertinent information.
The solution to the problem of searching for information on a specific science field can be Analysis Information Systems (IAS), which use agent technologies not only for indexing information but also to analyze and giving a hand to its users.
Agents, depending on their specialization, are able to aggregate information from various sources of information whether they are - sources of unstructured information (universities and institutes websites, commercial companies and news agencies sites) or sources of structured information such as "Web of Science", "ScienceDirect" databases.
In addition to the problem of collecting relevant information, there is the problem of visualizing information for analysis by the user. This article deals with the collection and visualization of information on special thematic areas, as an example the "Nuclear materials and Advanced nuclear reactors " was selected.
2. Methodology
2.1. Development of a thesaurus on monitoring objects
Search activities comprise the process of forming the thesaurus with monitoring objects. These activities are based on various search operations in information retrieval systems (IRS) such as Google and Yandex, as well as in conditionally opened databases such as Web of Science, Science Direct and Nexis. Each term in the thesaurus are is provided with its unique search pattern.
The search pattern is a template in the language of regular expressions, based on a term from the monitoring objects thesaurus and allows to perform an precise search by regulating the term position in a text, for example, taking into consideration morphology, register, number of lexical units occurrences within a compound term.
Search activities also comprise an identification of information sources based on principal of inclusion of relevant and reliable ones, along with algorithms for collecting information from various information sources[5].
While formatting the thesaurus of monitoring objects on the topic " Nuclear materials and Advanced nuclear reactors " 379 terms were found which include the names and abbreviations of projects, chemical elements, physical phenomena of reactor components.
The thesaurus was formed on the basis of the analysis of various IRS and databases search results after applying to them, relevant to this direction, simple and complex search queries.
The thesaurus is integrated into the database and allows carry out the full-text search and extraction of factual data from all information within the database (an example of a thesaurus is given in Table 1).
Table 1. Example of the thesaurus of monitoring objects in the field of " Nuclear materials and Advanced nuclear reactors".
|
№ |
Monitoring object |
Search pattern |
Register |
|
1 |
accelerator driven system |
(?<!\w)accelerator(.{0,3}?|(\s?\w+\s){0,2})driven(.{0,3}?|(\s?\w+\s){0,2})system |
case_insensitive |
|
2 |
acid deficiency uranium nitrate |
(?<!\w)acid(.{0,3}?|(\s?\w+\s){0,2})deficiency(.{0,3}?|(\s?\w+\s){0,2})uranium(.{0,3}?|(\s?\w+\s){0,2})nitrate |
case_insensitive |
|
3 |
active magnetic bearing for helium blower |
(?<!\w)active(.{0,3}?|(\s?\w+\s){0,2})magnetic(.{0,3}?|(\s?\w+\s){0,2})bearing(.{0,3}?|(\s?\w+\s){0,2})for(.{0,3}?|(\s?\w+\s){0,2})helium(.{0,3}?|(\s?\w+\s){0,2})blower |
case_insensitive |
|
4 |
ADS |
(?<!\w)ADS |
case_sensitive |
|
5 |
ADUN |
(?<!\w)ADUN |
case_sensitive |
|
6 |
advanced lead fast reactor european demonstrator |
(?<!\w)advanced(.{0,3}?|(\s?\w+\s){0,2})lead(.{0,3}?|(\s?\w+\s){0,2})fast(.{0,3}?|(\s?\w+\s){0,2})reactor(.{0,3}?|(\s?\w+\s){0,2})european(.{0,3}?|(\s?\w+\s){0,2})demonstrator |
case_insensitive |
|
7 |
advanced sodium technological reactor |
(?<!\w)advanced(.{0,3}?|(\s?\w+\s){0,2})sodium(.{0,3}?|(\s?\w+\s){0,2})technological(.{0,3}?|(\s?\w+\s){0,2})reactor |
case_insensitive |
|
8 |
advanced sodium technological reactor for industrial demonstration |
(?<!\w)advanced(.{0,3}?|(\s?\w+\s){0,2})sodium(.{0,3}?|(\s?\w+\s){0,2})technological(.{0,3}?|(\s?\w+\s){0,2})reactor(.{0,3}?|(\s?\w+\s){0,2})for(.{0,3}?|(\s?\w+\s){0,2})industrial(.{0,3}?|(\s?\w+\s){0,2})demonstration |
case_insensitive |
|
9 |
ALCYONE |
(?<!\w)ALCYONE |
case_sensitive |
|
10 |
ALFRED |
(?<!\w)ALFRED |
case_sensitive |
2.2. Information sources identification
Sources of structured information comprise data provided within well-structured data model and stored in a specific structure, which allow users to perform various analytic operations, for example, full-text search for specific attributes of the object. Web of Science and Science Direct are examples of such sources[3],[4].
Full-text databases, which are not applicable for search object using its individual attributes, and web portals, where information is presented in an unstructured manner, refer to unstructured data sources.
During the analysis of unstructured sources of information, about 90 websites of news agencies, companies, organizations around the world were identified. Moreover, the media and business information database “LexisNexis”, which collects information from more than 35 000 sources was decided to monitor. An example of the list of websites with daily information collection is given in Table 2.
Table 2. Websites on “Nuclear materials and Advanced nuclear reactors”.
|
№ |
Name |
Monitoring page |
|
1 |
allthingsnuclear.org |
http://allthingsnuclear.org/ |
|
2 |
cnnphilippines.com |
http://cnnphilippines.com/news/ |
|
3 |
dailynewshungary.com |
http://dailynewshungary.com/ |
|
4 |
en.interfax.com.ua |
http://en.interfax.com.ua/ |
|
5 |
en.mehrnews.com |
http://en.mehrnews.com/archive?all=1 |
|
6 |
eng.belta.by |
http://eng.belta.by/ |
|
7 |
english.aawsat.com |
http://english.aawsat.com/ |
|
8 |
ahram.org.eg |
http://english.ahram.org.eg/ |
|
9 |
english.sina.com |
http://roll.news.sina.com.cn/s/channel.php?ch=28#col=298&spec=&type=&ch=28&k=&offset_page=0&offset_num=0&num=60&asc=&page=1 |
Along with collection of structured data, specialized extended requests were formed. In addition to general requests on the subject area, highly specialized requests for monitoring objects were also formed to increase the completeness of the search result. For the following analysis of the obtained data from websites, specialized data converters that are able to convert data into the necessary data model for analysis were created.
Collection of information from sources with unstructured data is carried out with the help of agent technologies. An agent is a program that is activated according to a pre-planned schedule and has a certain level of autonomy for collecting information at a predetermined information resource on the Web. To monitor a large number of information sources, a specialized system was developed that performs the functions of manipulating agents, and also stores and processes incoming information. During the collection of materials for the "Nuclear materials and Advanced nuclear reactors" database, over 10,000 news reports were obtained in the first week, of which only 16 were relevant, indicating a low density of publication of information in this field.
3. Results
The integrated "Nuclear materials and Advanced nuclear reactors" database was formed by processing the search results of structured information databases such as Web of Science, Science Direct, Nexis and information messages from websites with unstructured information. Altogether, the integrated database comprises 599 relevant records. In addition to records on relevant topics, the integral database includes the thesaurus of monitoring objects and the life-cycle dictionary.
All records were processed in a factographic processor - the built-in software module which allows to extract the facts of the first and second order in an automated mode. To extract factual data, the program module requires a thesaurus of monitoring objects and a life-cycle dictionary that includes verbs that indicate a certain level of technological availability.
The facts extracting algorithm comprises further stages: splitting the incoming text into sentences in which the monitoring objects are searched and identifying the level of relevance. If thesaurus’ term in the sentence was identified, then this sentence becomes a fact of the first order[6]. To determine the fact of the second order, it is necessary to identify the monitoring object paired with the term from the life cycle dictionary.
Under data processing, all the information obtained was put in a general format, factographic data was extracted, and the pertinent database records were determined. Based on collected 599 records, a graph was constructed due to understand the scope and structure of the processed data for a user, and to provide users with function of clustering of materials based on the selected nodes and edges. The graph was constructed on the basis of Frouhterman Rheingold's algorithm (Figure 1). the Gephi software was used to construct the graph.
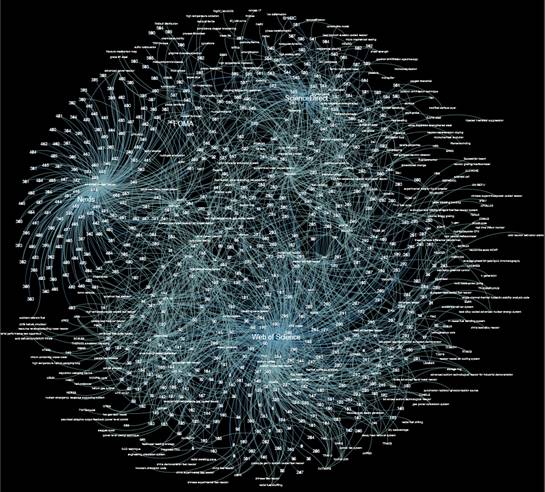
Fig. 1 The graph on the basis of Frouhterman Rheingold's algorithm.
The nodes of the graph are of three types of data: terms from the "Nuclear Materials and Reactors of the New Generation" thesaurus, sources types and the identification number of the relevant document.
By this means, a user can navigate the entire collection of documents. The graph allows to determine the most common concepts from the thesaurus and their relationship to the source.
Visual analysis of the graph allows to make operative conclusions about the occurrence of keywords from the thesaurus - the least common words are in the "outer orbit", the most common words are concentrated in the center.
Figure 2 shows a fragment of the graph that displays the connections between the keyword "advanced nuclear reactor" and the source of information, Nexis. On the basis of the graph, can be made conclusions about the belonging of material to the source - Nexis and the corresponding term - "advanced nuclear reactor".
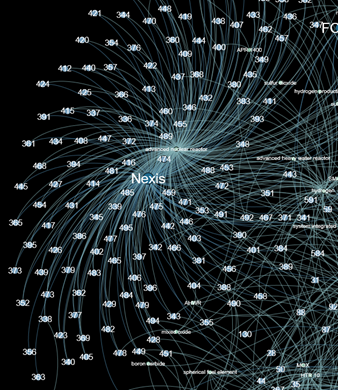
Fig. 2 Fragment of the graph.
Using the graph as a visual representation of the database allows the user to determine the most interesting materials for him and get acquainted with them directly in the integral database.
4. Conclusions
As the result of the measures taken to create a "Nuclear materials and Advanced nuclear reactors" database, a corresponding database was formed. To analyze the content of the database, the approach of visualization of information based on the construction of the graph was used. This method opened up opportunities for analyzing the concealed relations between database items on the basis of the transitions between the nodes of the graph, and also allowed the clustering of data based on keywords.
References
1. Onykiy B.N., Artamonov A.A., Ananieva A.G., Tretyakov E.S., Pronicheva L.V., Ionkina K.V., Suslina A.S. Agent Technologies for Polythematic Organizations Information-Analytical Support. Procedia Computer Science. Vol. 88. 2016. pp 336-340
2. Salton, G., McGill, M.J. Introduction to Modern Information Retrieval. (1986)
3. Abstract database Web of Science URL: https://webofknowledge.com/ (Date of access: 30.08.2017)
4. Abstract database Scopus URL: https://www.scopus.com/ (Date of access: 30.08.2017)
5. Artamonov A.A., Leonov D.V., Nikolaev V.S., Onykiy B.N., Pronicheva L.V., Sokolina K.A., Ushmarov I.A. Visualization of semantic relations in multi-agent systems. Scientific Visualization. 2014. Vol. 6. No. 3. pp 68-76.
6. Onkiy B.N., Tretyakov E.S., Pronicheva L.V., Galin I.Yu., Ionkina K.V., Cherkasskiy A.I. Methodology of Learning Curve Analysis for Development of Incoming Material Clustering Neural Network, Proceedings of the First International Early Research Career Enhancment School on BICA and Cybersecurity (FIERCES 2017). 2017. pp 133-138